Introduction
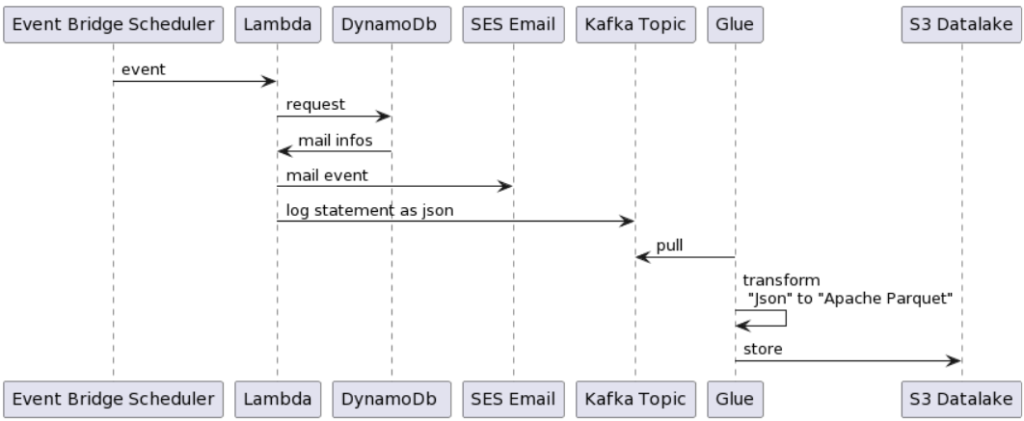
Our company recently ventured into a comprehensive R&D project that aimed at leveraging AWS Event Bridge Scheduler, Kafka, and Glue for sophisticated data processing. By combining various AWS services, we successfully established an efficient data processing pipeline. In this blog post, we will delve deeper into our findings, the challenges encountered, and the possible use cases for these services.
AWS CDK
AWS CDK (Cloud Development Kit) is a powerful infrastructure-as-code (IaC) framework developed by Amazon Web Services (AWS). It allows developers to define and provision AWS resources using familiar programming languages such as TypeScript, Python, Java, and others, instead of writing traditional declarative templates.
The decision to use AWS CDK over Cloudformation was mainly driven by the fact that we wanted to use a programmatic approach to provisioning and managing our cloud infrastructure. CDK offers a compelling alternative to static, declarative templates like AWS CloudFormation. By leveraging the power of programming languages, CDK enables you to use loops, conditions, and abstractions, making it easier to define complex architectures and manage dynamic resources. Further, if you and your team are already proficient in these languages, using CDK can leverage your existing skills and knowledge, reducing the learning curve associated with adopting a new tool like Terraform.
AWS Event Bridge Scheduler
We employed AWS Event Bridge Scheduler to automate our Lambda functions. The scheduleFunction method, responsible for provisioning the Event Bridge Scheduler, generates and assigns the necessary IAM permissions for invoking the corresponding Lambda function. Utilizing the cron syntax, we programmed our Lambda function to execute every night at 3:15 am, ensuring timely data processing:
scheduleFunction(approvalReminderFunction, "cron(15 3 * * ? *)");Schedule Lambda Function:
private void scheduleFunction(final Function function, final String scheduleExpression) {
.
.
.
Role schedulerExecutionRole = new Role(this, "schedulerExecutionRole", RoleProps.builder()
.roleName("ExecutionRole_" + function.getFunctionName() + "")
.assumedBy(principalLambda)
.managedPolicies(List.of(invokeFunctionPolicy))
.build());
CfnSchedule cfnSchedule = new CfnSchedule(this, "approvalSchedule", CfnScheduleProps.builder()
.scheduleExpression(scheduleExpression)
.flexibleTimeWindow(CfnSchedule.FlexibleTimeWindowProperty.builder()
.mode("OFF")
.build())
.target(CfnSchedule.TargetProperty.builder()
.arn(function.getFunctionArn())
.roleArn(schedulerExecutionRole.getRoleArn())
.build())
.build());
}
Lambda Functions
We developed two Lambda functions: ApproveReminder and PutUser, which process and store user data. These functions are integrated with Kafka to enable seamless data streaming.
Kafka Integration
To set up Kafka, we utilized AWS Managed Streaming for Apache Kafka (MSK), which facilitated storing log messages from our Lambda functions. Although this approach may not be optimal, it helped us gain hands-on experience with MSK and Kafka and understand their capabilities.
Kafka CDK Implemenation: Currently the L2 library for Glue is still in alpha state. Therefore the lib needs to be added as own maven dependency:
<dependency>
<groupId>software.amazon.awscdk</groupId>
<artifactId>msk-alpha</artifactId>
<version>2.68.0-alpha.0</version>
</dependency>
Costs of MSK
Unfortunately, MSK is quite expensive and so it’s important to know the main cost drivers to optimize your costs. Find the lost of main cost factors associated with AWS MSK below:
- Instance Types: AWS MSK uses Amazon EC2 instances as the underlying infrastructure. The cost of running MSK clusters depends on the chosen instance types, which determine the computing power, storage capacity, and networking capabilities. The hourly cost of instances varies based on the instance type selected.
- Instance Count: The number of instances in an MSK cluster affects the overall cost. The more instances you use, the higher the cost. You can adjust the instance count based on the performance and capacity requirements of your Kafka workload.
- Storage: AWS MSK clusters require storage to persist Kafka topic data and logs. The cost of storage is calculated based on the amount of data stored and the chosen storage volume type (General Purpose SSD or Throughput Optimized HDD). Additional charges may apply for data transfer and snapshots if enabled.
- Data Transfer: Data transfer costs may be incurred when there is communication between your MSK cluster and other AWS services, such as EC2 instances, S3 buckets, or data transfer across different AWS regions. These costs depend on the amount of data transferred and the AWS regions involved.
- Data Ingestion and Egress: If you receive data from external sources or send data out of AWS MSK to external destinations, there may be additional costs associated with data ingestion and egress. These charges vary depending on the amount of data transferred and the destination’s location.
- Additional Features: AWS MSK provides various additional features, such as encryption, monitoring, and access control, which may have associated costs. For example, enabling encryption at rest using AWS Key Management Service (KMS) incurs additional charges.
To reduce costs in our scenario, we used the smallest broker instances available (kafka.t3.small) and reduced to 1GiB storage. and use only 2 brokers in 2 availability zones each. Important note: The default size is kafka.m5.large with 100GiB storage and 3 brokers per availability zone. As we havve chosen default values first without checking if the default values do fit to our small usecase, we paid about 16€ per day unnecessarily.
AWS Kinesis as an Alternative
AWS Kinesis can be a viable alternative to AWS MSK when you want to run a serverless infrastructure for data streaming and processing. While AWS MSK is a fully-managed service for running Apache Kafka, AWS Kinesis provides a serverless streaming data platform.
Here are some points to consider when evaluating AWS Kinesis as an alternative:
- Serverless Architecture: AWS Kinesis is inherently serverless, which means you don’t need to provision or manage any infrastructure. It automatically scales to handle the incoming data stream, making it well-suited for serverless architectures. On the other hand, AWS MSK requires you to manage and scale the underlying EC2 instances.
- Stream Processing: Both AWS Kinesis and AWS MSK are designed for streaming data processing. AWS Kinesis provides the capability to ingest, process, and analyze large volumes of data in real-time using services like Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics. Similarly, AWS MSK supports real-time stream processing using Apache Kafka, which offers advanced features and ecosystem integrations for data streaming.
- Integration with AWS Services: AWS Kinesis integrates seamlessly with other AWS services, allowing you to build end-to-end serverless data processing pipelines. You can easily connect Kinesis with services like AWS Lambda, Amazon S3, Amazon Redshift, Amazon Elasticsearch, and more. AWS MSK also integrates with various AWS services but may require additional configurations and management.
- Cost Structure: The cost structure of AWS Kinesis differs from AWS MSK. With AWS Kinesis, you pay for the amount of data ingested, data stored, and data egressed. The pricing varies depending on the chosen Kinesis service and the associated data volume. AWS MSK, on the other hand, involves costs associated with EC2 instance types, storage, and data transfer.
- Complexity and Ecosystem: AWS MSK, being based on Apache Kafka, offers a rich ecosystem and advanced features for stream processing. It is well-suited for complex use cases and has extensive community support. AWS Kinesis, while providing powerful stream processing capabilities, has a more streamlined and simpler architecture, making it easier to get started quickly.
Ultimately, the choice between AWS Kinesis and AWS MSK depends on your specific requirements, architecture preferences, and familiarity with the tools. If you are already working within a serverless infrastructure or require a simpler setup, AWS Kinesis can be a strong option. However, if you have existing Kafka-based systems, complex streaming requirements, or specific Apache Kafka ecosystem needs, AWS MSK might be the more suitable choice.
AWS Glue
AWS Glue is a fully managed data integration service that empowers users to discover, prepare, and integrate data at any scale. We employed Glue to process data from our Kafka streams in microbatches every minute. While we encountered some challenges and limitations, such as inadequate documentation and lack of support for camel case fields, Glue Studio proved to be a valuable tool for generating ETL scripts and accelerating data transformation tasks. With AWS Glue you can discover, prepare, and integrate all your data at any scale. Its based on Apache Spark and support Scala and Python. The traditional usecase is to use S3 or DB as data source and process data with ETL style. In our showcase we used the streaming support from Glue. As input source we used AWS MSK (Apache Kafka) and process these data in microbatches once a minute.
Glue CDK implementation
Currently the L2 library for Glue is still in alpha state. Therefore the lib needs to be added as own maven dependency:
<dependency>
<groupId>software.amazon.awscdk</groupId>
<artifactId>glue-alpha</artifactId>
<version>2.68.0-alpha.0</version>
</dependency>
Glue Data Catalog
The data catalog defines the incoming and outgoing data structure and source/target connections. For Kafka/Kinesis/JDBC systems you need to define a connection. On the other hand S3 doesnt even need a connection is native supported. Once you have the connection you can create a table. In the table you define the data structure and format and assign your connection or S3 Bucket. Sooner or later you will have many tables, therefore you need to organize them and assign them to a database which is simly a visual wrapper containing tables. If you dont use streaming input you can also use a crawler which generates tables based on your example data.
Glue Studio & Jobs
You can use the Glue Studio to define a Glue Job. As input and output you select the tables defined in your glue data catalog. Next you can add some AWS provided visual transformations between your input and output steps. For example a visual transformation support aggregating data or filtering data much more options are available. In our streaming usecase we can select the microbatching window. The spark engine will then collect all Kafka messages for a defined period of time and process them together before writing it to the output place. In the Job parameters you have many options to configure the ressources you Spark Jobs will get or error handling options. In addition you can pass your own custom parameters which is quite useful for setting system environment specific values which is necessary for staging.
Once you defined your Job via Glue Studio it allows you to generate a Scala or Python script. We slightly modified the script with job parameters and then added it as source file into our CDK pipeline. However once modified you can no longer visually edit the script. In our showcase we used the Glue Studio just as template generator and then modified it with stuff which is not supported by UI. If you want to stay on the visual approach AWS supports a custom transformation which lets you add code without breaking visual editor support. However we are not sure if its possible to copy that job code into CDK and still being able to edit it visually. Find a Screenshot of Glue Studio right below:
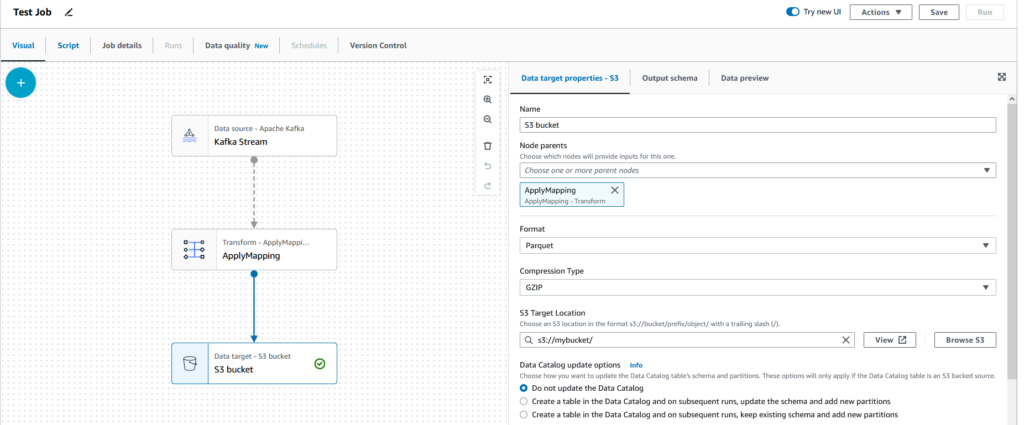
Glue triggering
In our streaming showcase the Glue job is running nonstop waiting for defined period to process messages and then for the next period. If your datasource is for example s3 you can schedule job runs or you can configure s3 events to start a job run.
VPC Setup
We placed our glue jobs in the same VPC where the Kafka Cluster was running. Therefore we add to create a VPC Gateway Endpoint to s3 to allow Glue access to resource outside of our VPC.
Issues with Glue
- CDK L2 does not support Kafka connection: As a workaround we used autogenerated L1-Tables in our GlueStack. In total it took us quite much time to setup Glue via CDK until we found the proper setup.
- UI Defects: There are several small non critical problems in the glue studio UI. For example if you create a new job and adjust the jobName it automatically adapts the „Script filename“. However if you try to start a new job and you get a validation message to adjust the job name, then it does not automatically adapt the „Script filename“. Or another example is that if you stop a job its state goes into „stopped“ but if you want to start it one second later it says that the job is still running. And there are much more such mall non critical issues.
- Camel Case support missing: Currently table columns in the Data Catalog do not support camel case fields, only lowercase letters are allowed. In our example we had a json field like „executionTime“. We really had to adjust our datasource to parse this field. We contacted AWS support and the confirmed thats a known issue. In our option thats quite a big issue if you dont want to add a workaround like we did.
- Kafka IAM authentication not working: We started our project with Kafka IAM authentication. We tried to use the AWS Web Console to establish a connection but we didnt manage to get it working. Then we created an AWS support case. After discussion with the support we found out that there is some issue on AWS side and the AWS support promised to open a feature team ticket to address this issue in the future but he mentioned currently there is no ETA. For our showcase project we decided to completly remove authentication from MSK and we followed for some parts the guide the AWS support sent us: https://github.com/liangruibupt/glue-streaming-etl-demo/blob/master/IoT-Kafka-GlueStreaming-Demo.md
- Poor cloudformation documentation: If you are new on glue its quite hard to find all the documentation. We think AWS could improve the documentation. For example if i want to set a table parameter, you dont find the details on the cloudformation guide here: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-table-storagedescriptor.html#cfn-glue-table-storagedescriptor-parameters. It just says you can add paramters. But you need time to search other documentation pages to find the required parameters for kafka or kinesis. For Glue beginners it would be really helpful to quickly find which paramters without doing a reserarch for it.
Future of Glue
For our future projects we think that AWS still has some work to implement in order to get a full stable and feature rich product. First of all we would like to see a stable CDK release. Next we think the issues mentioned should get fixed to avoid other teams running into the same problems. We really liked the Glue Studio approach which can help you speed up implementing standard transformation tasks without knowing the Spark Api or even being familar with Python/Scala. But we think AWS is still at the beginning and should add much more standard transformations to Glue studio to get a powerful visual product. We saw already a coulpe of new transformations for 2023 so we are postiv to see more this year.
Cost Considerations
The cost of using MSK can be high. However, we managed to mitigate expenses by opting for smaller broker instances, minimizing storage, and reducing the number of brokers per availability zone. Glue can also be costly for small data volumes, but it is more suitable for processing large batches of data asynchronously.
Potential Use Cases and Follow-up Ideas
AWS Glue is versatile and can be utilized for a variety of data processing tasks, including filtering, aggregating, and preparing data for dashboards or machine learning use cases. However, it is not the ideal choice for real-time processing or small data use cases. Based on our research, here are some potential follow-up project ideas:
- Integrating S3 output with Amazon Athena and Amazon Quicksight to construct operational dashboards, providing real-time insights into business performance.
- Leveraging Glue output for machine learning to create CloudWatch operational alerts, enhancing system monitoring and anomaly detection capabilities.
Challenges Faced
During our R&D project, we faced several challenges, such as: Poor documentation for AWS Glue, making it difficult for beginners to understand the necessary parameters for various configurations. Glue’s lack of support for camel case fields in the Data Catalog, which required us to adjust our data source for proper parsing. Some UI defects in Glue Studio that, although not critical, impacted the user experience.
Conclusion
Our R&D project provided valuable insights into harnessing the power of AWS Event Bridge Scheduler, Kafka, and Glue for advanced data processing. Despite some limitations and challenges, these services can be combined to create efficient data processing pipelines for a variety of use cases. As AWS continues to enhance and expand their offerings, we eagerly anticipate exploring new possibilities for data processing and integration in future projects.

