Introduction
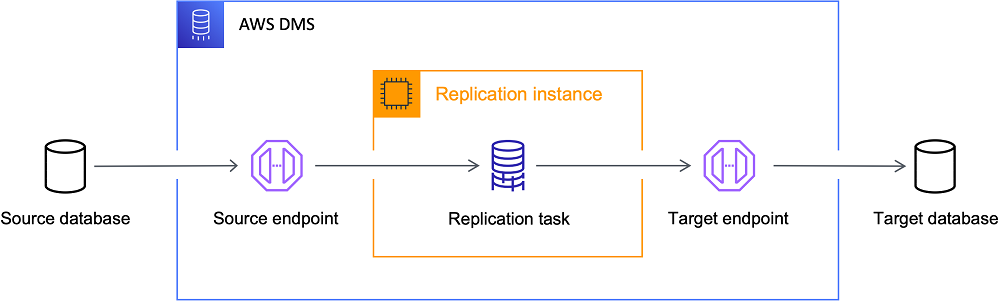
The AWS Database Migration Service (DMS) is a service that can be used for migrating a database from On-Premise to the AWS Cloud but also for in-place migrations in AWS. AWS DMS is used to minimize the downtime when performing database migrations.
Use-Case
We evaluated AWS DMS to do a DB migration from Postgres 11 to Postgress 15 with minimal downtime. Our postgres DB is running in an AWS RDS instance and since we want to split up our database to multiple RDS instances, we couldn’t go for the usual upgrade path of AWS RDS. Migrating our RDS by doing an export from the source database and import to the two target instances, would take a lot time, leading to a downtime of several hours.
Limitations
Depending on the type of source and target database, there are some limitations of DMS. Generally when using DMS for a DB migration, it will only create the tables and primary keys. Everything else needs to be migrated by hand, e.g. user, indexes, functions, sequences. 1
AWS provides a guide on the prerequisites and conditions, depending on the source and target database types that are used:
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.html
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.html
AWS DMS Setup
There are different components that need to be created before a migration task can be set up and executed. The creation differs for the database and network setup in AWS and depends on the location of source and target database. In our case source and target instances were RDS instances and they were located in the same VPC, therefore I’m going to show the setup for this case. If needed, AWS provides examples for other setups as well:
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_ReplicationInstance.VPC.html
Subnet Group
Creating a subnet group is fairly easy, just choose the VPC where your databases are located and afterwards select the subnets to add to the group. With the setup of having source and target database in the same VPC, private subnets should be chosen for the subnet group.
Replication Instance
For creating the replication instance there are a few things that need to be considered:
- Instance class – This depends heavily on the source database and the amount of data to migrate. In our case we learned, that memory optimized instance classes provide the best performance and we went with the R5 class.
- High availability: For production workloads it’s recommended to use the Multi-AZ Setup, this will create a second standby replication instance in a separate availability zone.
- Storage to allocate – Usually DMS doesn’t use too much storage during the migration. We migrated a database that contained 3 TB of data and choosing 100GB storage for the replication instance was totally sufficient.
- Public access – Not needed for our single VPC setup.
Endpoints
To get started with the usage of endpoints, we first need to have an IAM Role and IAM Policy in place. This policy is used for the migration itself, but also for the access of the RDS secrets and to write data of the migration task to a S3 bucket. In-depth settings are described in the AWS DMS documentation: https://docs.aws.amazon.com/dms/latest/userguide/security-iam.html.
For each migration task we need to have two endpoints defined, one endpoint pointing to the source database and one endpoint that points to the target database. When creating an endpoint, you can choose the corresponding RDS instance and define if it’s the source or target database. For authentication to the database either a secret from the AWS Secretsmanager can be defined or the username and password can be set manually in the endpoint settings.
Also important to know, in the endpoint you define the database that you want to migrate. Meaning if you migrate multiple databases of one RDS instance, you’ll need to set up two endpoints for each database.
DMS Migration Tasks
There are two different types of migration tasks that can be executed:
Full Load
A full load describes the migration of all existing data of a database or a table / set of tables. If there are changes in the tables that are being migrated, those changes will be cached on the replication instance until the full load is finished. Afterwards all the cached changes are applied to the target database as well.
Change Data Capture (CDC)
CDC describes the on-going replication of data between the source and the target database and it usually follows after a full load migration, to keep the two databases in sync. After the full load is done and the cached changes are applied, DMS collects changes as transactions and applies them to the target database. Depending on the amount of transactions, this might lead to a lag between collecting transactions from the source database and applying them to the target database.
The easiest way to start the CDC task is as a follow-up task to the full load migration, because you don’t have to define a start point for the ongoing replication. If this is not possible there are two ways to define starting points for a CDC task:
Custom CDC start time
You can define a specific start time by providing a timestamp to the DMS task settings. DMS will then convert that timestamp to a native start point, e.g. to a LSN for SQL databases or SCN for Oracle databases. This method is not valid for all types of databases, because Postgres can’t convert the timestamp to a native start point.
CDC native start point
A CDC task can also be started from a native starting point that can be retrieved from the transaction log. This is usually more reliable, since a timestamp could potentially point to multiple starting points in the transaction log. Detailed information on how to retrieve the starting point can be found in the AWS Documentation: https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Task.CDC.html#CHAP_Task.CDC.StartPoint?icmpid=docs_DMS_help_panel_hp-dms-classic-tasksettings-cdcstart-source
Task Settings
Running a full load for a huge database can take a lot of time. We tested a migration for a 3TB database and it ran for almost 30 hours and there were a lot of validation errors. The time can be reduced though by choosing the right configuration settings, as well as getting rid of the validation issues. Instead of running a migration for the whole database with the same settings, it makes sense to pick the biggest tables of that database and create distinct migration tasks for those tables. In our case those tables were easy to identify, we just checked the full load for the whole database for the longest running tables.
Setting up parallelisation:
To set up parallelisation for a migration task, it’s required to have a primary key that is suited for splitting up the table entries into ranges. For example an ID column that is numbered consecutively would be the best option. Now we need to figure out the lowest and the highest ID by running:SELECT min(ID) FROM table_x;SELECT max(ID) FROM table_x;
Assuming the lowest ID is 1 and the highest is 10000, we now need to create equal ranges between those two numbers:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "public",
"table-name": "table_x"
},
"rule-action": "include"
},
{
"rule-type": "table-settings",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "public",
"table-name": "table_x"
},
"parallel-load": {
"type": "ranges",
"columns": [
"ID"
],
"boundaries": [
[
"1000"
],
[
"2000"
],
[
"3000"
],
[
"4000"
],
[
"5000"
],
[
"6000"
],
[
"7000"
],
[
"8000"
],
[
"9000"
],
[
"10000"
]
]
}
}
]
}This will run several tasks in parallel, the first one would be all IDs lower or equal than 1000, the next higher than 1000 and lower or equal than 2000 and so on. Equal to the first boundary, the last one will be applied for all IDs equal or higher than 10000.
To make sure that multiple tasks can be executed in parallel, we need to adjust the MaxFullLoadSubTasks setting to a proper value. Setting it to 8 – 10 would be a good starting point in regards to the above defined boundaries.
Having a lot of migration tasks with many subtasks being executed in parallel, we need to monitor the source database, target database and replication instance resource usage. Especially the validation of migrated records causes load on the target database. If the parallel load is too high for the replication instance to handle, we can either adjust the instance type or create multiple replication instances and spread our tasks across the different instances.
Setting maximum LOB size:
In the migration task, there’s a setting called maxLobSize and it’s crucial for the validation to be executed successfully. The default is set to 32kb, but this most often is too low. For each migration task, we need to find out the table and column that contains the most data by e.g. running SELECT max(length(column_x)) FROM table_x;
Now we can set the maxLobSize to a value that’s a bit higher than the retrieved value from the query. In case the validation is still failing for some of the entries in our database or table, we need to increase the maxLobSize even further.
Migration Workflow
A workflow to do a database migration with minimal downtime involves the following steps:
- Create a migration task with migration type ‚Migrate existing data and replicate ongoing changes‘, which will initially copy all existing data to the target database and afterwards continues with replicating ongoing changes.
- Create a validation only task, that will validate your migration continously during the replication of ongoing changes.
- At some point, if the migration is running fine without any validation errors, stop the traffic to the old database and wait until there are no more ongoing changes being applied to the target database.
- Switch traffic of your applications to the target database.
Summary
The AWS Database Migration Tool is a really powerful and useful tool for running database migrations, but it’s also not a tool that is easy to use by just running it with default settings. There are a lot of things to keep in mind and to test and adjust over time. Depending on how much time it takes to get familiar with AWS DMS and preparing and testing the migration, it needs to be evaluated if the minimal downtime is worth that effort. Especially with a lot of databases and tables, it’s sometimes tedious to figure out which setting is useful for which task and how to spread the load over different instances.
Nevertheless, once the knowledge is gathered and preparations are done, it’s a great tool to run the database migration over time and let the changes being synced continiously to finally cut over from the old to the new database. Being able to minimize the downtime of a database migration can be a huge gamechanger in certain usecases.
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Troubleshooting.html#CHAP_Troubleshooting.General.MissingSecondaryObjs ↩︎

