In June 2021 project Shipwright was promoted as the new way how to build images in OpenShift. Around this time project Shipwright (not being OpenShift specific) was marketed by Red Hat as OpenShift Builds V2. However, this naming has now (Feb 2023) apparently fallen into disuse again.
Nevertheless, project Shipwright is still kicking and it may become the future of building images in OpenShift. Remarkably, Shipwright borrows some concepts and resources from Tekton – the cloud native successor of Jenkins. Shipwright leaves several building blocks of Tekton aside (namely Pipelines and PipelineRuns) and adds its own resources.
So, as both projects (Tekton and Shipwright) try to succeed to some legacy technology (Jenkins and OpenShift Builds) and Shipwright is partly based on Tekton we will cover both in this article about the future of building in OpenShift.
Let’s start with Tekton…
Tekton
Tekton isn’t specific for building images. Of course its focus is continuous integration / continuous delployment (CI/CD), but in general it’s an all-purpose framework to model and run all kinds of automated procedures. There are several custom resources and concepts that closely work together. Understanding these building blocks and their interaction is vital for understanding Tekton as a whole.
To avoid confusion it has to be mentioned that Tekton in the OpenShift 4.x world is marketed by Red Hat as OpenShift Pipelines. It ships with a curated set of Tasks. The OpenShift console has some elements to list and monitor existing Tekton resources. Apart from these two aspects there is no difference between Tekton and OpenShift Pipelines.
A graphical overview of some of the involved components:
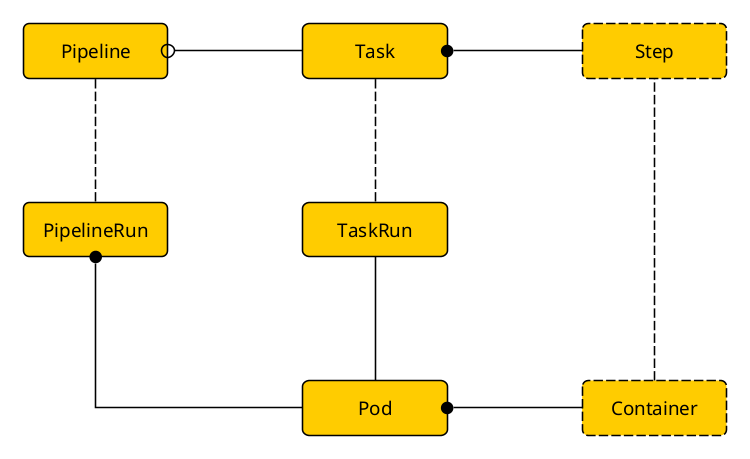
Resources
Tasks
One of Tekton’s key objectives is reusability. This is achieved (among others) by Tasks. Tasks are items that can be combined into pipelines. Tasks are typically parameterized so that they can be used in a flexible way. (E.g. a task to fetch sources code from a repository typically offers parameters like a repository URL, branch name, credentials, optionally a sub-tree within the tree of source files, etc.)
Tekton offers two types of tasks: Task and ClusterTask. The first is namespaced, i.e. it exists within a certain namespace and can only be used in this namespace. ClusterTasks on the other hand are available cluster-wide. Apart from this scoping aspect there is no difference between the two types. When defining a Pipeline it doesn’t make any difference whether the Pipeline references a Task or a ClusterTask.
Steps
A Task consists of one or more steps. Steps aren’t distinct resources but are defined within a Task. It is worth mentioning that a running Task is represented by a Pod and that the steps of the task actually map to containers running within this Pod. Consequently one of the vital properties of a step is an image specifier.
There are many more details about steps to be found in Tekton’s documentation.
Pipelines
Tasks can be combined into longer procedures called Pipelines. Similar to Tasks arguments can be defined for a Pipeline. These can be used in many places of Pipelines and Tasks. E.g. Pipeline parameters can be passed on to Task parameters. Tasks can return result parameters that can be referenced in later Tasks.
Tasks aren’t simply executed in the order they are defined within the Pipeline, but execution sequence is defined declaratively by fields named runAfter. This is especially helpful in case some tasks can (or should) be run in parallel. It’s also possible to execute certain Tasks conditionally. For any condition slightly more complex than just checking the value of some string parameter you need to implement and run a separate condition container.
Tasks can also be referenced in a finally section to ensure certain Tasks are run at the end of the Pipeline – no matter whether the Pipeline terminated successfully or prematurely due to some failure.
Workspaces
One concept that is used by both Pipelines and Tasks is Workspaces. These are simply a redirection to volumes. The concrete nature of a workspace – be it an EmptyDir volume, an existing PersistentVolume, a read-only volume backed by a ConfigMap, etc. – is determined somewhere else (just read on).
Workspaces are the typical means to transfer content from one Task to another (or even from one Step in a Task to another Step). E.g. one Task may be responsible for cloning a git repository. The cloned code is stored in a workspace and acts as input in a later build Task. The artifacts compiled during the build Tasks are also stored in a workspace (not necessarily the same). A subsequent buildah Task copies these artifacts into a new image as specified by a Dockerfile.
PipelineRuns
An actual run of a Pipeline is represented by an instance of (you guess) PipelineRun. This is the resource where parameters of a Pipeline are assigned concrete values. This is also where the volumes backing workspaces are defined. There are several options how the latter can be accomplished. One especially interesting option is VolumeClaimTemplate. This is not a separate resource but a section within a PipelineRun. It causes the automatic creation of a PersistentVolumeClaim that in turn triggers the provisioning of a new PesistentVolume that is used for a certain Workspace.
A PipelineRun resource remains even when the concrete execution of the Pipeline has finished. And so does the automatically created PersistentVolumeClaim and the provisioned PersistentVolume. Deleting the PipelineRun (either implicitly by some policy or explicitly) causes all owned resources (Pods, ConfigMaps, PersistentVolumeClaims, PersistentVolumes, etc) to be deleted too by means of owner references.
TaskRuns
TaskRuns are similar to PipelineRuns, but only run a single Task instead of a Pipeline. We will look into these more detailed when talking about Shipwright.
Review
We have implemented dozens of Pipelines (including some custom Tasks) for one of our customers and have been using these for several months. Time for a review.
Coding and maintenance
Tekton is not easy. The learning curve is quite steep. Getting familiar with the product is comparable complex as with Jenkins. The lack of a DSL (domain specific language) in Tekton or the option to express Pipelines in one of several all-purpose languages is a true downside. Coding everything in YAML dispersed among several resources plus functionality in custom images makes it difficult to keep an overview. Except for descriptions of parameters there is no possibility to comment YAML code. (You may abuse annotations to put some documentation there, but that is not the intended use of annotations.)
It requires strong discipline to put your code (YAML for Tekton resources, Dockerfiles and scripts for custom images) under version control and keep the resources in your OpenShift project consistent with the code in your code repository. It happens so easily to simply edit one of your resources with oc edit and forget to bring your local YAML code in sync. No git status that reminds you of uncommitted changes. (ArgoCD to the rescue, you may think. But then you lose any option for experiments and quick round trips. Every single trial becomes a commit, even that garbage you produced at the end of a long working day out of sheer desperation.)
All in all maintenance is hard, code becomes convoluted and scattered over several places (Pipelines, Tasks, scripts in various images). Don’t expect to grasp all details of code that you have written yourself a couple of months ago.
GUI
Tekton has no native GUI. The OpenShift console offers a dedicated item in the main menu on the left (administrator view) about Pipelines. It allows to list existing Pipelines, Tasks, Triggers (see below) and builds. The insight into running or already finished PipelineRuns and TaskRuns is really helpful and goes beyond what you can achieve on the command line with oc and tkn. Creating and modifying Pipelines at least looks impressive. We haven’t used this option – so cannot assess its usefulness.
Starting a Pipeline (i.e. creating an instance of PipelineRun) boils down to providing all information regarding parameters and workspaces – and may become tedious. There is no option to start a Task (i.e. to create an instance of TaskRun).
Starting a Pipeline or a Task
Starting a Pipeline (or a Task) basically requires creating an instance of PipelineRun (or TaskRun). You have (at least) three options:
GUI: Start your Pipeline (or Task) via GUI by providing values for all parameters and defining all workspaces. This can become tedious – and annoying when you have to provide the same values again and again for each PipelineRun. Rerunning previous PipelineRuns helps a lot, but you have this naming issue (read on).
Starting a Pipeline via GUI lacks the possibility to name the instance – something that corresponds to the attribute metadata.generateName in the YAML code of a PipelineRun instance. Instead, the instances are all named with the Pipeline’s name plus a 5 character random code (e.g. -5xng1). This causes a special annoyance when you make use of the reusability offered by Tekton. By providing different input parameters you may be able to build quite different output (in our case base images) with the same Pipeline. Unfortunately, all PipelineRuns have basically the same name. You cannot see by their name which PipelineRun produced which output.
tkn: Another option is the Tekton specific command line tool tkn. Starting a Pipeline (i.e. creating an instance of PipelineRun) requires a command like e.g.:
tkn pipeline start sample-pipeline \
--prefix-name sample-run- \
--param git-url=https://github.com/openshift/ruby-hello-world \
--param git-revision=dev-branch \
--param target-imagestream=ruby-hello-world \
--workspace name=shared-workspace,volumeClaimTemplateFile=ruby-vc-template.yaml \
--workspace name=ssh-dir,secret=ssh-files \
--showlog
Quite a mouthful! And this example is not exaggerated. (Did you spot that part where details are delegated to a separate file named ruby-vc-template.yaml?) If you go this way you will sooner than later resort to writing all kind of wrapper scripts containing commands like this.
tkn has its uses, e.g. tkn pipelinerun logs --follow, but starting a Pipeline is not one of its strengths.
It has to be mentioned that tkn has its problematic corner cases, e.g. array parameters where one of the array items contains a comma.
Creating instances of PipelineRun (or TaskRun): The third option is to create instances of PipelineRun (or TaskRun), i.e. compile a YAML file and feed it to oc create -f. This may sound even more cumbersome than the second option with tkn. But as already said, almost certainly you will end up writing wrapper scripts around your elaborated tkn pipeline start commands. So there is no big difference to writing a piece of YAML code. With the latter you have full control of every aspect offered by PipelineRun (or TaskRun). Finally, kicking off a PipelineRun becomes a matter of (e.g.) oc create -f my-pipelinerun.yaml.
We have refined this last approach even further by putting the YAML code and the call of oc create -f into a custom build. Finally, starting a Pipeline became oc start-build <custom-build> --follow. Bonus: we got image change triggers (non-existing in Tekton), source change triggers (complex to implement in Tekton) and aggregated build out for (nearly) free. See this blog article for all the nifty details.
Build logs
Speaking about build logs: As already mentioned a PipelineRun triggers one pod for each Task comprising the Pipeline and each step (and each non-trivial condition) of a Task is represented by one container within the Task pod. So build logs are finally scattered across a whole bunch of containers in various pods. Following build logs synchronously with the oc tool is impossible. This is one of the aspects where tkn shines. With tkn pipelinerun logs --follow you can easily follow the output of your PipelineRun.
The above mentioned solution with the PipelineRun created with a custom build also takes advantage of tkn pipelinerun logs --follow with the added benefit that tkn needs not to be present at the user’s machine. tkn is baked into the image used by the custom build. Output of tkn pipelinerun logs --follow becomes the output of the custom build, i.e. you can use oc logs build/... or oc start-build ... --follow to view the build output.
Eventing & Triggering
Tekton dedicates a whole subproject to the domain of processing events and triggering PipelineRuns (or TaskRuns). The following custom resources come into play here: EventListener, Interceptor (optional), TriggerBinding, TriggerTemplate and Trigger. As you can see from this impressive enumeration the concept is super flexible, super powerful, but also super complex and pretty difficult.
In the end establishing an endpoint, verifying and processing the content of incoming requests, and creating instances of PipelineRun or TaskRun is no magic at all. This can be achieved with any serious programming language with all the expressive power that comes with this language. No need to re-invent the wheel and cast everything in YAML. A collection of a few pre-fabricated images with the option to drop in the request processing part in the form of a script or a method would have been far more helpful than this bloat that comprises Tekton Eventing & Triggering.
What’s more: Tekton Eventing & Triggering is all about events coming in in the form of HTTP(S) requests. A whole class of events is silently ignored – events generated within Kubernetes. For instance we were not able to implement image change triggers only with Tekton means. (We found a workaround for this deficiency. But still, it remains a workaround.) Or someone might be interested in kicking off a PipelineRun when a new namespace has been created. The domain of operational automation could be covered – at least partially. No chance with Tekton.
Hacking pod semantics
The general approach of Tekton is to represent a running Task by a Pod and the steps comprising the Task by containers. This may sound charming – but it has its drawbacks.
One is that steps need to be run sequentially whereas containers in a Pod are actually run in parallel. Tekton applies a tricky hack to force Kubernetes to effectively run the containers sequentially. Basically the entrypoint of an image used for a step is replaced by a Tekton specific binary. This binary controls the starting of the original entrypoint and monitors the ensuing process. It communicates with the same binaries in the other containers of the Pod via semaphors and files in a shared volume. It can become tricky to determine the original entrypoint – especially when the image was loaded from a remote registry requiring credentials. Again see Tekton’s documentation for details.
Requests and Limits
Another challenge arising from the way how containers are run in Tekton is how to deal with requests and limits for CPU, memory and ephemeral storage – not to forget about maxLimitRequestRatios. By the original Kubernetes semantics the requests and limits of the containers of a Pod simply sum up (leaving aside init containers). Things become quite complicated when Tekton forces containers to effectively run sequentially (while in reality they actually still run in parallel – but simply wait most of the time). Tekton’s documentation dedicates a whole chapter to this area (remarkably not mentioning maxLimitRequestRatios at all). The whole field has already undergone several iterations.
Conclusion
All in all, the use of Tekton has not been as convincing as expected. Writing and maintaining Tekton pipelines is complex, tedious and error prone. A graphical user interface would be a big plus. Same applies for a domain specific language (glueing together some kind of plugins hiding the complexity of specific tasks).
Of course taking advantage of a Kubernetes cluster for running build pipelines is something that suggests itself. Spinning up more than one container per build can make sense – especially in the case of concurrent build paths and when doing complex automated integration tests that require several mock systems connected with the system under test. But the approach of mapping each step and each non-trivial condition to a separate container is at least questionable. It is over-engineered and causes more issues than gains.
Shipwright
As already mentioned project Shipwright strives to become a successor of OpenShift Builds – thus Red Hat came up with the name OpenShift Builds V2. It takes advantage of Tekton’s TaskRun and builds upon this foundation with its own concepts and resources. As a consequence Shipwright adopted from Tekton the fundamental concept of a Task mapping to a Pod and the Steps executed in the context of this Task mapping to separate containers.
Contrary to Tekton, Shipwright is focused on building images. It also takes an opinionated stance in that input is always taken from a git repository. No other options. (The documentation mentions source bundle images without further explanations to be found anywhere.)
A graphical overview of Shipwright building blocks, where Tekton TaskRun comes into play and how this maps to Pods and Containers
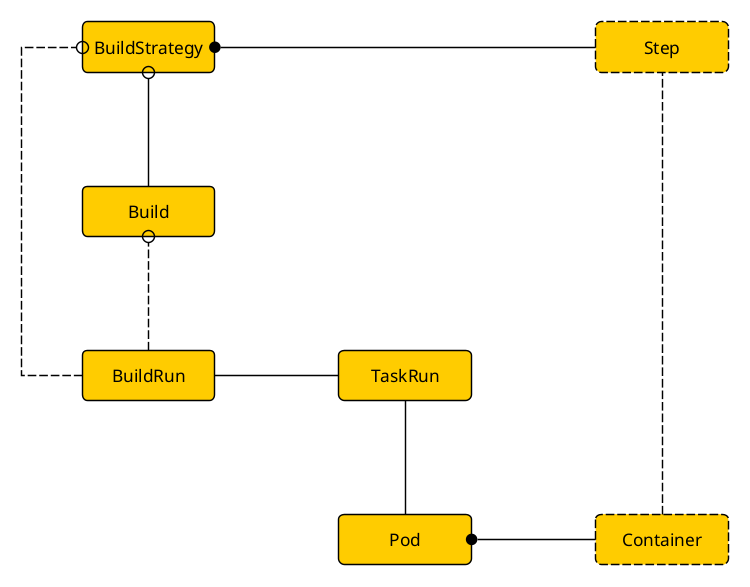
Resources
BuildStrategy (and ClusterBuildStrategy)
Instances of resource type BuildStrategy (namespaced) or ClusterBuildStrategy (cluster-wide) are at the heart of Shipwright’s resources. They can be regarded as fragments of Tekton Tasks (or ClusterTasks). They specify parameters and steps (here called buildSteps). Shipwright inherits from Tekton the approach that each step later maps to one container. Consequently each buildStep requires (among other things) the specification of an image to be used when the corresponding container materializes.
Shipwright ships with an asorted set of ready-to-use BuildStrategies. They represent most of the current approaches how to build container images: buildah, buildpacks v3, kaniko, buildkit, ko and source-to-image.
Build
Next come the resources of type Build. They reference a BuildStrategy (or ClusterBuildStrategy) and specify where to get the sources from for this build and where to put the result (i.e. the URL of the resulting image). Additionally certain parameters defined by the (Cluster)BuildStrategy can be fixed to a specific value. Same applies for volumes. A volume required by a BuildStrategy can be defined in a Build. (There are more things that can be specified. They are not essential for understanding the overall concept. See the documentation for details.)
BuildRun
Instances of BuildRun (as the name suggests) actually kick off a concrete build, i.e. you will end up with a Pod and one or more containers that actually build something. Basically there are two options how to specify a BuildRun:
- The BuildRun references a Build. In case not all parameters have already been specified in the Build (or in the BuildStrategy) the BuildRun is the last resource where missing values can be provided. There is also the option to override certain parameters as need arises. Similarly volumes must be defined in case they have not already been defined in the Build – and there is also the option to override a volume definition inherited from the Build.
- Second a BuildRun can omit to reference a Build and provide all necessary information in a
buildSpecsection. This is basically a Build embedded into a BuildRun instance. (See the dotted line in the above diagram from BuildRun to BuildStrategy bypassing Build.)
An instance ob BuildRun can be created either via Shipwright’s command line tool shp (1). Or by coding a YAML file and creating an instance by means of oc create. The controller responsible for BuildRuns collects all the information from the BuildRun, optionally from a referenced Build and the involved BuildStrategy and creates an instance of Tekton’s Taskrun. This is where Shipwright actually makes use of Tekton resources and controllers. In turn the TaskRun controller spins up the Pod and the containers corresponding to the build steps of the BuildStrategy do their job.
Review & Conclusion
I haven’t used Shipwright for real life builds, just played around to get an impression.
A definitive plus is the option to use other tools than buildah to build images. (Buildah is used by OpenShift builds under the hood.) There is nothing wrong about buildah, but it is always good to have other options.
On the other hand Shipwright inherits the intricateness of Tekton. It leaves out Pipelines and PipelineRuns, but introduces BuildStrategies, Builds and BuildRuns. To me the introduction of Builds seems pointless as you have the option to specify everything in a BuildRun, not making use of any Build. You have a YAML file specifying a BuildRun that you can use as often as you like to start a certain build without the need to modify anything in the YAML file. Maybe the benefit of Builds only becomes apparent when you have lots of different builds in a real life scenario.
Having said so it also has to be mentioned that handling resources of type Build is a permanent nuisance – at least on OpenShift. OpenShift already has a resource type named Build. Working on the command line (there is currently no other option) you always have to make explicit that you mean Shipwright’s Builds – not OpenShift’s, i.e. oc get build.v1alpha1.shipwright.io/buildah-python -o yaml. Apparently the creators of Shipwright didn’t have OpenShift in mind when choosing the names of their resources. In this regard is remains a mystery that Red Hat (after having introduced Shipwright as the new image building infrastructure for OpenShift (OpenShift Build V2)) didn’t stumble over this … peculiarity.
Speaking about OpenShift Build V2: It’s been more than 20 months now (Feb 2023) since Red Hat announced that Shipwright will become OpenShift Build V2. And Shipwright is still beta. And even more, the beta status currently is just an announcement. The last release (v0.11.0) from 2022-09-09 was still alpha! And no new release since then. Doesn’t look like a vibrant project.
Documentation leaves a lot of room for improvement, not only because of its poor English and lots of dead links.
All in all Shipwright appears to be in a sad state. From today’s perspective I doubt that it will eventually become OpenShift Build V2.
Note 1: The documentation of shp is rudimentary, only listing all commands, subcommands and options.