Whenever systems are subject to a change we have to uphold compatibility to the clients. Any change that breaks a contract (technically or semantically) will in best case lead to traceable malfunction or in worst case to a broken, but silently proceeding system. In most cases when we change API contracts we just extend the old contract. In practice breaking changes will occur. Good news is that there is a strategy called „Expand and Contract“-pattern which also plays well together with modern platforms.

In a further, not yet published blog post and code repository, I will describe everything step by step with code examples using Kubernetes.
The problem of a breaking change
We should not do that, right? We often try hard to not break any API and add a lot of technical debt to the system just because it was designed in a way that doesn’t work anymore for new features we have to add now. From that experience, that’s also when developers try to find the very best solution for any possible future and over-engineer things for new features. And that’s where software development can get very slow and nevertheless at some point in the future we would like to break our API to not implement the workaround for the workaround, which means that whatever we consider for our design:

Don’t spend too much time preparing for every eventuality as things will always change. Rather pick the easiest solution, which is good enough for now and know how to easily change it in the future.
Although we have tooling for deployments we are responsible on our own to patch our software that it doesn’t break and the patch itself has to match the deployment strategy. Luckily there is a pattern called „Expand and Contract“ which doesn’t need any sophisticated tooling or technology and describes a strategy of changes in software that will in sum apply a breaking change by consecutive small non-breaking changes.
Expand and Contract
We start with an overview of the essential parts of that pattern. It basically starts with the expand-phase and ends with the contract-phase. Applying the whole change at once break the system, but going through all phases in order makes it work. The central idea is that in a client-server relation at first the server has to expand and allow the clients to use that extension. After a few steps, we can contract everything and clean up the old implementation. It works the same for server with database, where the server actually is the client in that relation.
A common use case is a breaking change in the database model, where the data structure for a new feature doesn’t work anymore and should be altered. The following steps are described with a Canary Release, which is the default rollout strategy in Kubernetes.
1 – Expand phase
At first we start with a running system, where we identified Table X to be changed because for example the cardinality in table will not work anymore with a new feature and we have to prepare that in order to be able to implement the new feature.

Instead of changing and migrating everything with the next version, we start with the „Expand“-phase and create a new table Table N that contains the new structure and our Server v2 should keep everything as is, but write updates also to Table N. Notice that with the introduction of Table N the information content and source of truth Table X stayed the same. Because we now keep partial duplicated information it is inconsistent, due to Server v1 will not update Table N.

The goal is to guarantee that Server v2 will not introduce new inconsistencies from a consistent state, writing to Table X and Table N . Thus writing to both tables should be executed in a transaction.

Before we bring both tables to a consistent state, we need to make sure, that all Server v1 instances are drained, because they would introduce new inconsistent data.
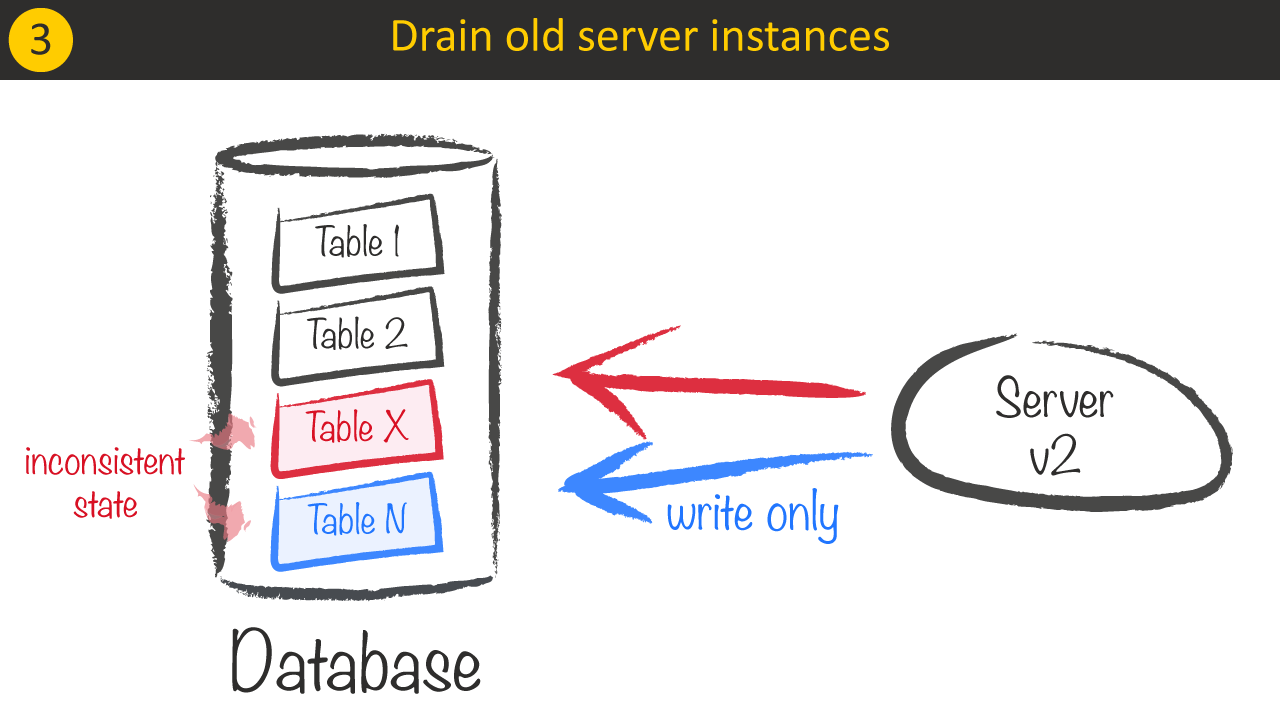
2 – Migrate
As soon as all Server v1 instances have been gone it’s guaranteed that a migration to a consistent state will uphold consistency from that point on. The migration should take care, that still the source of truth is Table X and it should only change Table N. The good thing is that the migration job can be split into arbitrary sized chunks of work to not overload the system and the migration step is not time-critical at all, so the system can run in this state for a longer time. In other words the migration makes the data converges iteratively to a consistent state while migrated data stays consistent.

After the migration we should be able to verify over time that the data really stays consistent. We could therefore let the system run for a while.
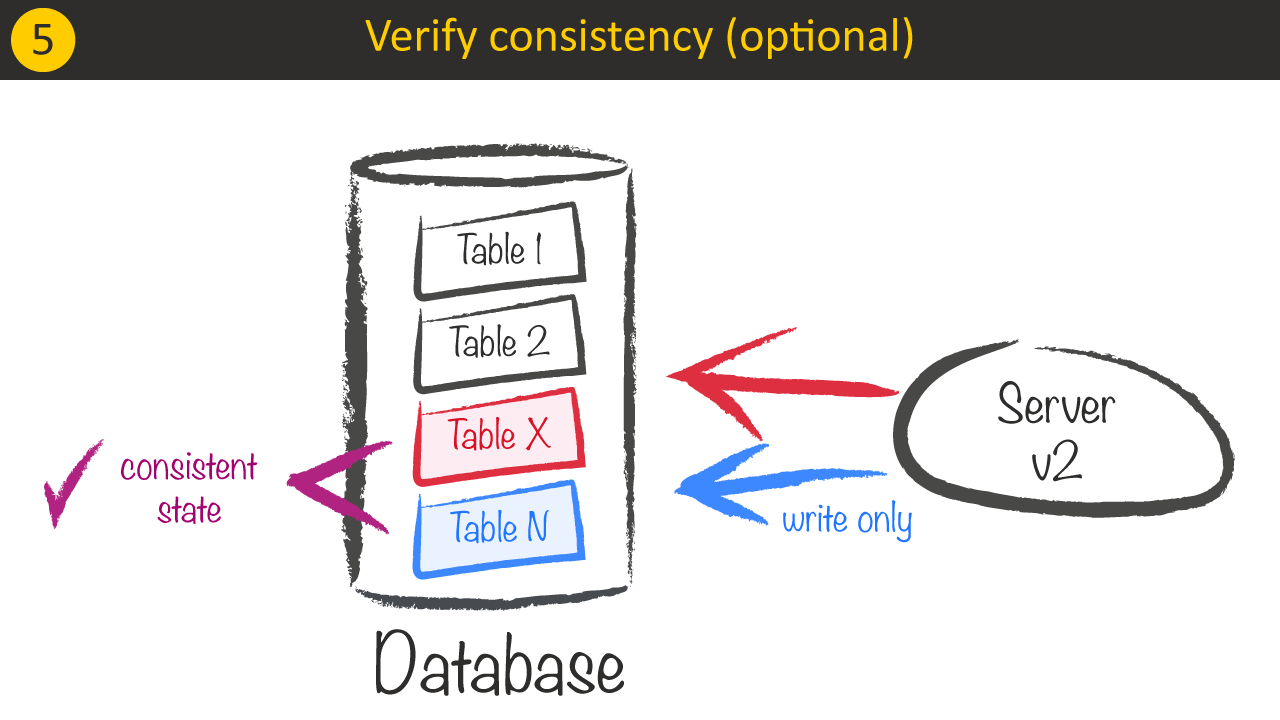
3 – Contract phase
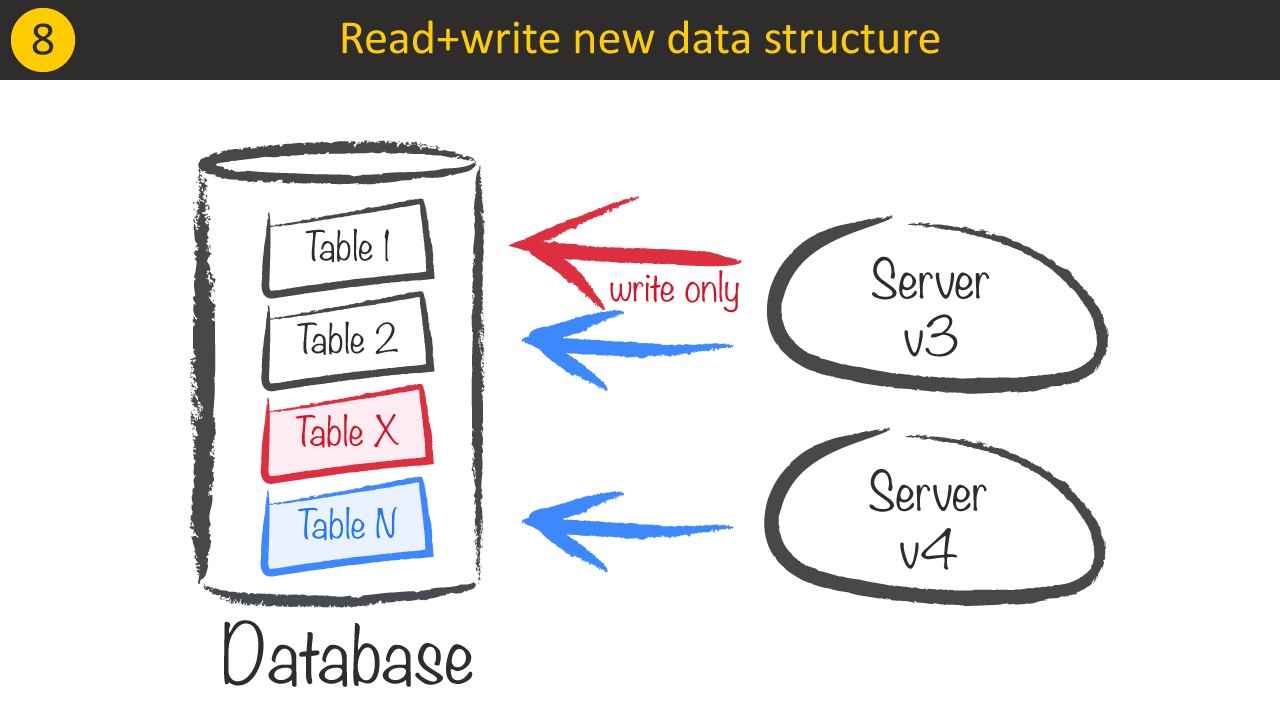
With a better confidence that our system does the right thing for the change, we can now launch our Server v3 which does the same as Server v2 but symmetrically inverted. It should now use Table N as the source of truth for reading and writing and write to Table X.
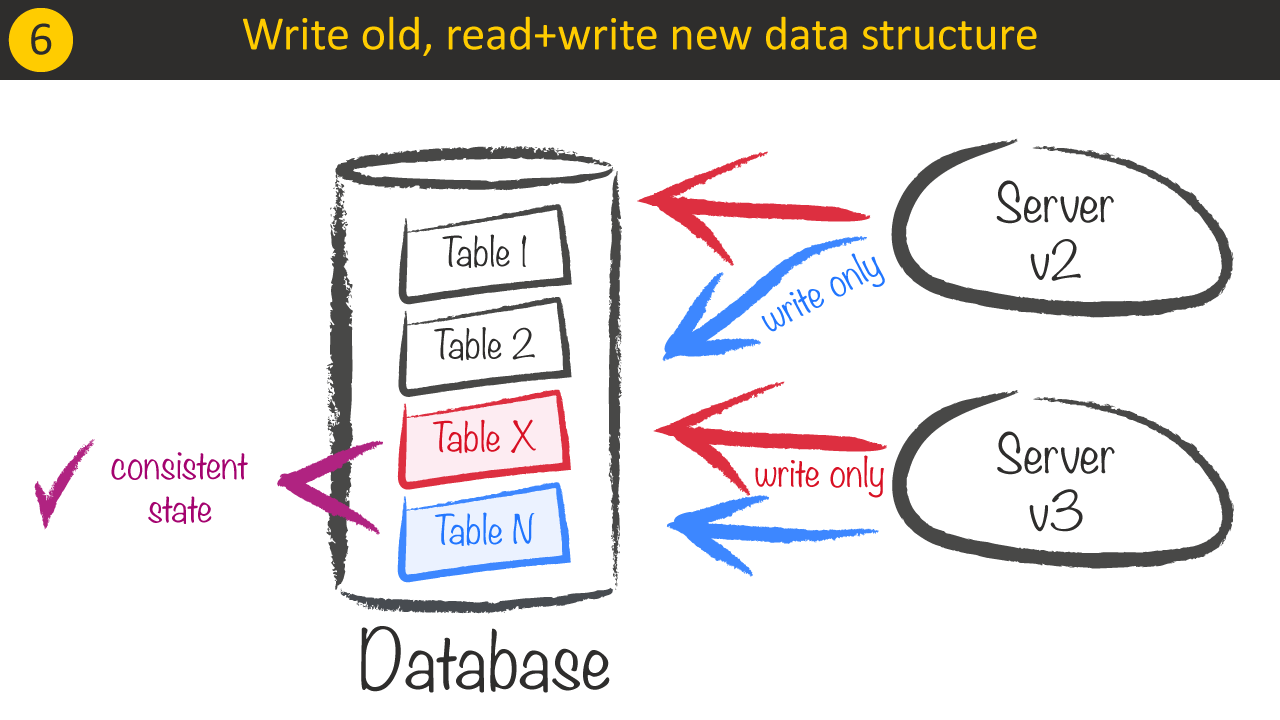
Before we deploy our last version, which uses Table N as source and not using Table X anymore, we need to make sure that no Server v2 instances are running anymore, as the last version (again symmetric to Server v1 at the beginning) will introduce inconsistent data between both tables as Table X is not updated anymore.

Last but not least we deploy a version that only uses the new structure Table N thus again introduces inconsistent data as Table X is not updated anymore.
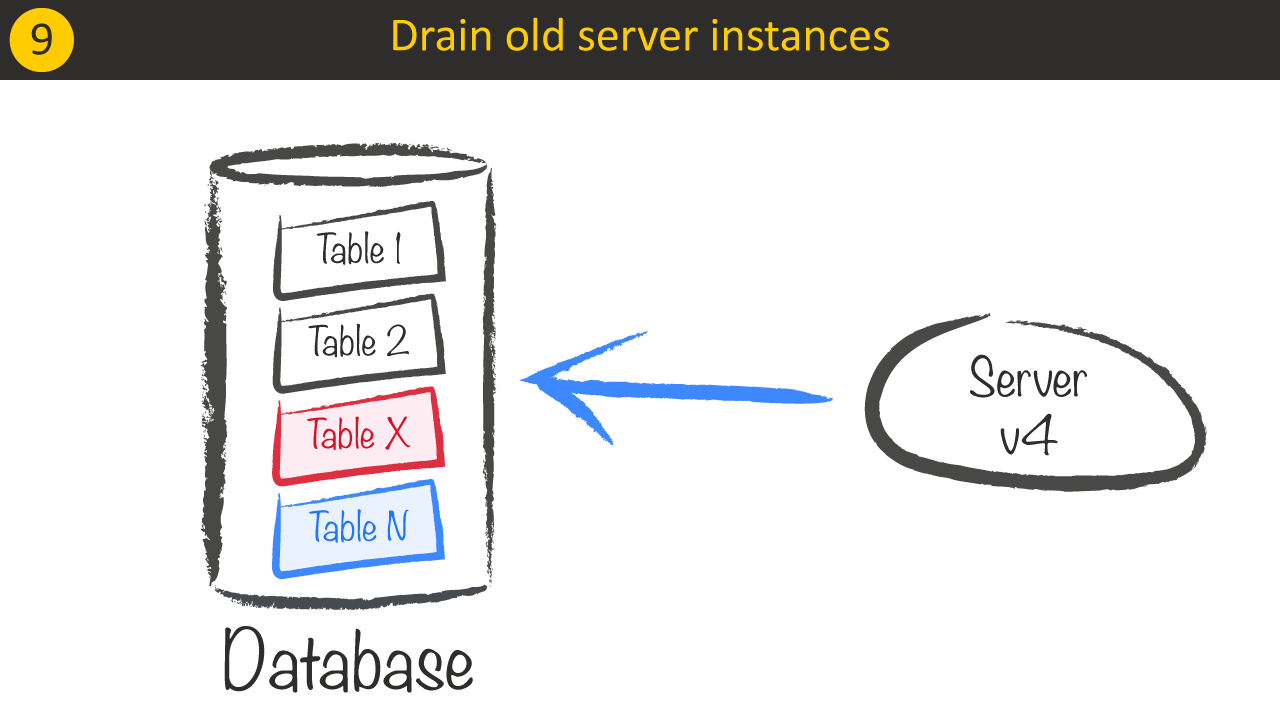
Before we’re allowed to clean up and remove Table X we need to drain Server v3 instances.
For the last deployment the server is allowed to remove Table X.
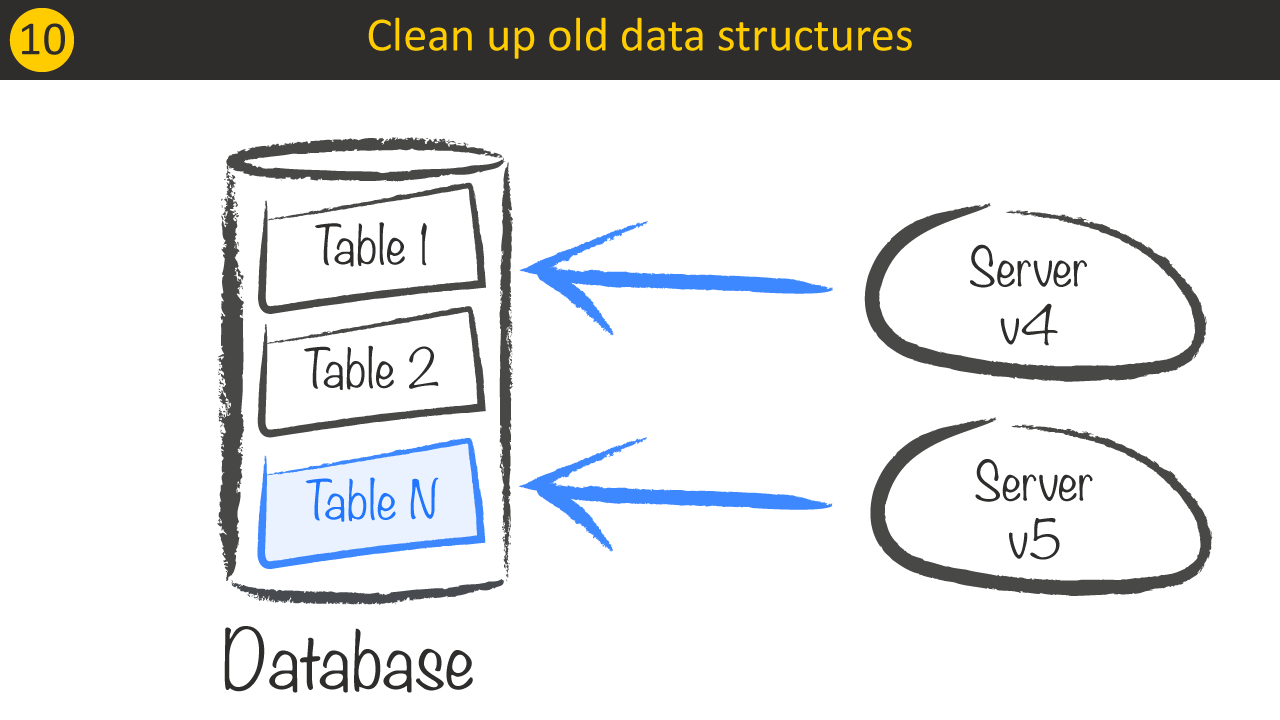
Finally after all Service v4 instances has been stopped we have successfully rolled out a breaking database change on a productive system.

Recap – Expand and Contract
As a short recap here are all steps in one diagram:

Each server version will have a single source of truth for reading, while possibly writing data to more than one source.
Breaking changes in practice
Companies often go a quicker, but riskier way and do a Blue-Green deployment, where the „Green“ version breaks the „Blue“ version and put the change together with the migration in one step. The higher risk is also often tried to be compensated by a defined service downtime window and/or deployments outside the business hours, if possible. Depending on the criticality of the service, as well as the extent of the change and other factors, the „quick way“ can become a severe problem when rolling-back the breaking change was not consider or for some reason doesn’t work because it wasn’t properly tested. With Expand and Contract going back one version is always possible.
Conclusion
Utilizing Expand and Contract means more overhead, but a smooth and solid transition without any „point of no return“-barriers, as well as no time pressure at all. Every deployment step will allow to rollback one version if found faulty. There are no downtimes and a possible large migration job can be split into smaller tasks to reduce delays for concurrent requests.
Even though this pattern could be considered a secret weapon for any type of system change, it also often turns out that it’s not necessary, because we don’t have to meet all the requirements the pattern can fulfill. Another underestimated aspect is that changes can become very complicated. Starting with some infrastructure setups that may not support easy, automated deployments and finally the implementation itself may turn out to be very complex, because of the business domain. Try to find your solution according to your own taste.
Outlook
As already mentioned the Expand and Contract pattern can get quite complex even for smaller changes. To be able to focus on the change itself it’s good to have a solid platform that allows for convenient deployment and rollback. One of them is Kubernetes and in Part 2 I’ll show you how to use it to rollout a breaking change, step by step.
If you’re interested in having your own bullet-proof platform for development and production, just feel free to reach out to us to help you.